随着生成式AI重塑信息获取方式,生成式引擎优化(GEO)成为提升内容在AI回答中可信度与引用优先级的关键策略。本文系统阐述GEO实践框架,强调通过知识原子化、Schema.org结构化标注、内部知识图谱构建及多模态适配,使内容更易被AI理解。同时建议通过事实核查、权威信源引用、专家关联与持续监控,增强内容权威性,并展望未来向知识即服务与AI智能体调用的演进方向,助力企业在AI时代构建产品心智护城河。
引言
技术的演进正在改变用户获取信息的方式。过去,用户习惯于通过搜索引擎获取一个链接列表,再自行筛选和判断。如今,以ChatGPT、Gemini、文心一言为代表的生成式AI,可以直接针对用户问题生成一个整合后的答案。
这种变化对内容创作者和技术团队提出了新的挑战。过去我们关注的重点是如何在搜索结果中获得更高的排名(Ranking),现在则更需要关注内容如何被AI模型有效理解、采纳并用于生成答案。信息如何进入AI的知识库,以及其内部的权重判断和生成逻辑,是当前技术社区普遍关心的问题。

本文将探讨的生成式引擎优化(Generative Engine Optimization, GEO),可以看作是应对这一变化的技术框架。它将优化的重心从传统的网页排名,转向提升信息在AI生成结果中的可信度和引用优先级。本文将尝试梳理GEO的技术结构与实现思路,为相关从业者提供一个可供讨论的实践框架。
一、基本原理:从信息索引到知识整合
1.1 用户信息获取路径的改变
传统搜索引擎扮演的是“信息索引器”的角色,它向用户提供一份信息目录。而生成式AI更像一个“信息整合器”,它试图直接交付处理后的最终答案。
这意味着用户的信息获取链路被显著缩短,从“搜索-点击-比对-决策”的流程,简化为“提问-获取答案”。在这种模式下,用户可能更倾向于信任AI提供的首个答案,这使得“第一答案”的质量和准确性变得至关重要。
1.2 内容可见性面临的新挑战
这种模式的转变,给内容方带来了两个值得关注的技术问题:
- 内容采纳的不确定性: AI模型的知识库来源广泛,其内部的信息抽取与整合逻辑对外界而言尚不完全透明。我们发布的内容能否被AI准确“理解”并“采纳”,存在一定的不确定性。
- 直接流量的变化: 当AI直接提供答案时,用户访问源网站的需求可能会降低,这可能影响到传统基于网站流量的分析和转化模型。
1.3 GEO的核心目标:成为AI生成答案的优质信源
面对上述挑战,GEO的目标是清晰的:在特定领域或问题下,使自身内容成为AI生成答案时优先考虑的、可信赖的引用来源。
这意味着,当用户提问时,我们希望AI的回答能够准确地反映我们的信息,甚至在可能的情况下,引用我们的数据、定义或方法论。这要求我们将优化的重点,从追求泛化的流量,转向提升内容在AI知识体系中的权威性和准确性。
二、技术基石:构建AI可读的结构化知识体系
要让AI模型更精准地理解和引用信息,首要任务是让信息对机器“可读”和“友好”。这意味着内容需要从面向人类阅读的“文章”,转变为机器易于解析的“结构化数据”。
2.1 知识原子化:内容的模块化处理
“知识原子”是指构成知识体系的最小、独立的知识单元,如一个产品参数、一个技术定义、一个操作步骤等。
传统的文章是知识的“聚合体”,包含上下文和叙事逻辑,这对于AI提炼核心事实可能引入干扰。知识原子化的过程,就是将这些聚合体拆解为独立的、事实明确的知识单元。
例如,一篇介绍“XX数据库”的产品文档,可以拆解为以下知识原子:
- 【产品定义】XX数据库是一款分布式时序数据库。
- 【核心特性】写入性能:支持每秒千万级数据点写入。
- 【核心特性】查询延迟:典型查询延迟低于50毫秒。
- 【适用场景】适用于物联网设备监控。
- 【安装步骤1】下载最新版本的安装包。
- 这个过程为后续的结构化标注提供了清晰的素材。
2.2 结构化标注:使用Schema.org与AI对话
结构化标注是使用AI能理解的词汇表,为“知识原子”贴上标签。Schema.org是一套被主流搜索引擎和AI模型广泛支持的通用词汇表,它提供了一套标准的标签体系。
通过在网页中嵌入这些标签,我们可以明确告知AI“这段文字是一个问题的答案”、“这个列表是一个操作指南”,从而降低AI的理解成本,减少信息误判。
2.2.1 几种重要的Schema类型
在GEO实践中,以下几类Schema标记与常见查询类型直接相关:
Schema 类型 用途说明 对GEO的价值
Product 描述产品,包括名称、品牌、价格、特性等。 帮助AI精准获取产品参数,用于对比和推荐类问题。
FAQPage 标记一组“问题-答案”对。 优化问答类场景,AI可能优先从标记页面中抽取答案。
HowTo 标记一个分步骤的操作指南。 成为“如何做XX”这类问题的权威信源。
Article / TechArticle 标记文章,包含作者、发布日期等元数据。 建立内容的权威性(Authority)和时效性(Recency)。
Organization 描述一个组织,包括官方名称、Logo等。 确立官方身份,帮助AI区分官网与第三方信息。
2.2.2 JSON-LD:推荐的实现方式
JSON-LD (JavaScript Object Notation for Linked Data) 是当前推荐的Schema实现方式,其优势在于:
- 部署灵活: 可作为独立的脚本标签插入页面,与HTML结构解耦。
- 可读性强: 键值对结构清晰,便于人和机器解析。
- 扩展性好: 适合表达复杂的实体关系。
- 以下是一个结合Product和FAQPage的JSON-LD示例:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Product",
"name": "QuantumLeap Database",
"image": "https://example.com/quantumleap_logo.png",
"description": "QuantumLeap Database是一款专为AI应用设计的高性能向量数据库。",
"brand": {
"@type": "Brand",
"name": "FutureTech Inc."
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.9",
"reviewCount": "1250"
},
"offers": {
"@type": "Offer",
"priceCurrency": "USD",
"price": "999.00",
"availability": "https://schema.org/InStock"
},
"mainEntity": {
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "QuantumLeap Database支持哪些索引类型?",
"acceptedAnswer": {
"@type": "Answer",
"text": "我们目前支持HNSW和IVF-Flat两种主流的ANN索引类型,能够平衡查询速度与召回率。"
}
},
{
"@type": "Question",
"name": "部署QuantumLeap需要什么硬件配置?",
"acceptedAnswer": {
"@type": "Answer",
"text": "推荐至少使用16核CPU、64GB内存及NVMe SSD硬盘以获得最佳性能。详细配置请参考我们的官方文档。"
}
}
]
}
}
</script>2.3 内部知识图谱构建:连接实体与关系
在完成大量知识原子的结构化标注后,可以通过内部链接将它们有机地串联起来,形成一个内生的知识图谱。
- 统一命名实体: 为每个核心概念(如产品名、技术术语)创建一个唯一的、权威的定义页面。
- 强关联链接: 在所有提及该实体的页面中,都使用内部链接指向这个权威定义页。
这个过程有助于AI在处理查询时,优先采信网站内部已经形成的清晰知识网络,减少对外部信息的依赖和可能产生的歧义。
2.4 多模态内容适配
随着多模态大模型的发展,结构化工作也应延伸到视频、图像等非文本内容上。
- 视频内容: 为视频的关键章节、时间轴添加结构化描述。
- 图像内容: 撰写详尽的alt-text,并使用ImageObject Schema标记提供元数据。
- 表格数据: 使用规范的HTML 标签呈现参数对比表,而非图片。
三、实践策略:提升内容的权威性与影响力
完成基础的结构化工作后,下一步是通过主动的内容和分发策略,提升内容在AI眼中的“可信度”。
3.1 应对AI幻觉:建立事实核查机制
AI有时会生成不准确的信息(即“幻觉”)。我们可以主动采取措施进行校准。
- 建立“事实核查”页面: 在官网上创建“Fact Check”或类似板块,针对行业内的常见误解或不实信息,发布官方的、准确的声明和数据。
- 坚持数据优先: 在内容中多使用可验证的、精确的数据,代替模糊的主观描述。AI在整合信息时,更倾向于引用有明确来源的客观数据。
- 明确边界条件: 在描述一个技术或产品时,清晰地界定其适用范围和局限性,有助于降低AI在推理时发生错误关联的概率。
3.2 成为高质量信源:提升内容的权重
让内容从被动等待AI爬取,升级为AI模型训练或知识库构建时愿意参考的“上游信源”。
- 向核心平台贡献高质量资产:
- GitHub: 开源高质量的代码、SDK和技术文档。
- arXiv: 发布与技术相关的学术论文或预印本。
- Hugging Face: 分享经过清洗和标注的数据集。
- 构建“多源互证”的信任链条:
- 在内容中,显性地引用和链接到更高维度的权威信源,如行业标准、权威机构报告(如Gartner、信通院评测)、顶级学术论文等,构建一个相互佐证的信任网络。这与SEO中的E-E-A-T(经验、专业、权威、可信)理念一脉相承。
3.3 建立领域定义权
在细分领域,努力成为新概念、新方法或新范式的“首创者”和“定义者”。当一个新概念由你首次提出,并被行业广泛引用时,你的内容就成为了这个概念的“知识地标”,在AI的知识图谱中占据了核心位置。例如,Google通过论文定义了“Transformer架构”,使其成为该领域无法绕开的信源。
3.4 关联权威专家
将内容与领域内公认的专家进行关联,可以显著提升可信度。
- 内容实名署名: 深度技术文章由核心技术专家实名署名,并附上其个人履历和成就。
- 专家活动背书: 专家参与行业标准制定、在顶级会议演讲等活动,也能反哺内容本身的权威性。
四、监控与反馈:动态迭代的闭环
GEO是一个需要持续监控和优化的动态过程。建立一套有效的监控和反馈体系至关重要。
4.1 AI问答表现监控
我们需要一套机制来追踪主流AI引擎在提及我们相关内容时的表现。
4.1.1 核心监控指标
监控指标 定义与说明 监控工具/方法
提及频率 在特定主题问答中,相关内容被AI主动提及的次数。 使用脚本或第三方工具,批量模拟用户提问并统计。
上下文类型 内容被提及时的上下文是正面、负面还是中性? 人工审计与NLP模型结合,进行情感分析和意图识别。
信息准确性 AI生成的信息是否准确,是否存在错误或过时信息。 将AI回答与官方的“事实清单”进行自动化比对。
引用来源 AI提供的引用来源是官网、权威第三方,还是其他? 自动化爬取和分析AI回答中的引用链接。
回答漂移 随着模型更新,同一问题的回答内容是否发生变化。 建立历史回答快照库,定期进行差异比对。
4.1.2 监控的实现思路
可以搭建一个简易的监控系统,包括:定义核心问题集、通过API调用实现模拟提问、利用NLP技术分析回答、生成监控报告并在发现严重问题时告警。
4.1.2 监控的实现
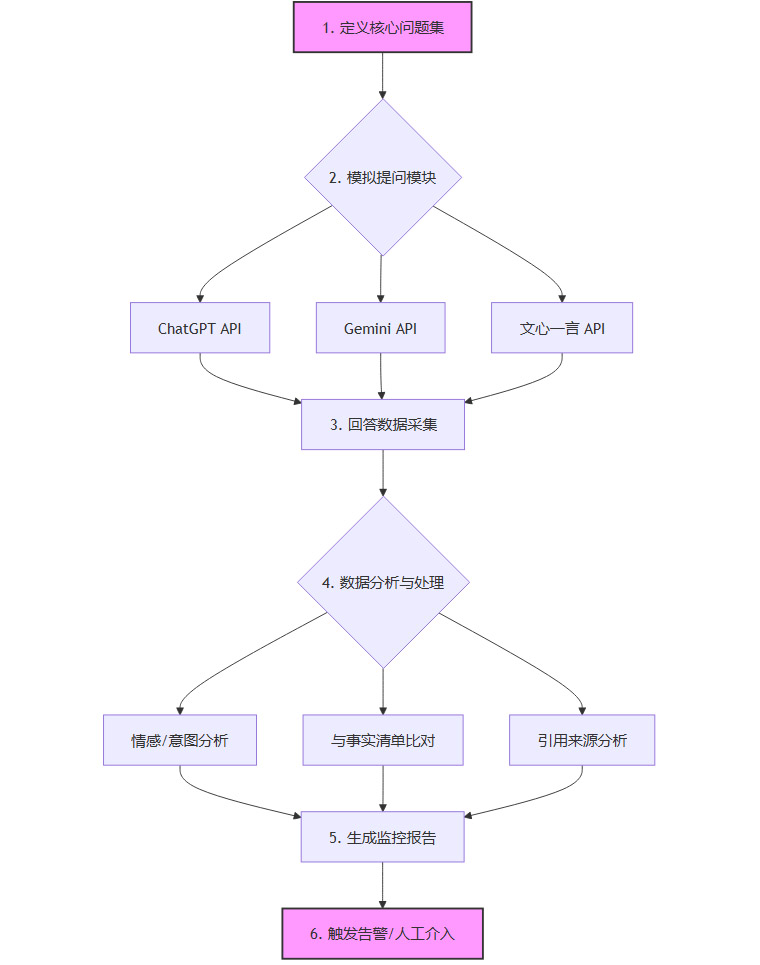
建立这套监控系统,通常需要技术投入。
- 核心问题集:由产品和市场团队共同定义,覆盖品牌、产品、技术、竞品对比、解决方案等关键场景。
- 模拟提问模块:通过脚本调用各大AI平台的API,实现高频、自动化的提问。
- 数据分析与处理:利用NLP技术对采集到的回答进行分析,并与内部维护的“事实清单”进行比对。
- 监控报告与告警:将分析结果可视化,形成周报或月报。当发现严重负面信息或事实错误时,触发实时告警,通知相关团队介入。
4.2 负向反馈与修正流程
当监控系统发现问题时,可以参考以下流程进行快速响应:
- 结构化修正: 立即在官网(如“事实核查”页面)发布一篇针对该错误信息的、结构化标记完善的更正文章。
- 广域放大: 将这篇更正内容,通过合作的权威渠道进行分发,以在短时间内形成关于“正确信息”的声量优势。
- 主动提交: 利用AI平台或搜索引擎提供的问题反馈入口,主动提交更正文章的链接。
- 持续验证: 将相关问题加入高频监控列表,持续追踪AI的回答是否被修正,并根据结果迭代优化策略。
五、未来展望:从被动优化到生态融入
5.1 对技术与产品人员的新要求
GEO的实践,对技术和产品人员提出了新的能力要求。除了关注用户流量,还需要具备“知识架构师”的思维。
核心职责思考:
- 规划知识体系:定义需要对外输出的核心知识原子和实体关系。
- 设计内容结构:确保产出的内容对AI友好且结构化。
- 推动技术实现:推动Schema标记、监控系统等基础设施的落地。
- 衡量内容影响:用GEO相关指标来衡量内容在AI世界中的影响力。
5.2 GEO的演进方向:从“被引用”到“被调用”
当前阶段,GEO的讨论主要集中在如何让内容更好地“被AI引用”。从更长远的角度看,其终极形态可能是从“被引用”升级为“被调用”。
- 知识即服务 (Knowledge as a Service): 品牌可以探索如何将自身的结构化知识库,通过API的方式开放出来,成为一个可供其他应用或AI智能体(Agent)调用的“知识服务”。
- 成为Agent的核心工具: 未来的AI应用可能会由许多垂直领域的智能体构成。如果一个品牌的API和知识图谱,能成为这些垂直Agent执行任务时首选的工具集,那么它就建立起了生态级的优势。
结论
生成式引擎优化(GEO)是传统内容优化思想在AI时代的一次自然演进。它并非要完全颠覆SEO,而是在其基础上,将重心从“排名”转向“知识”,从“流量”转向“信任”。其核心在于将内容进行系统性的数字化、结构化、权威化,以更好地与AI的认知逻辑对齐。

对于技术开发者和产品经理而言,理解并实践GEO的理念,有助于在新的信息范式下,提升自身内容的技术价值和影响力。这需要我们以更严谨的架构思维和跨学科的视野,去构建和维护我们的知识资产。
作者:「天枢InterGPT」




评论列表 (17条):
加载更多评论 Loading...